



Agent skill files have a reputation for being insecure, and that reputation is earned.
When we launched ClawHub alongside OpenClaw, we were immediately targeted by actors who tried to publish skills bundling known malware. We partnered with VirusTotal to flag those skills and ban the publishers automatically.
Traditional malware scanning is a relatively solved problem. Identifying agentic risk is not. A skill can claim to summarize your logs while bundling a script that ships them off your machine. A well-meaning skill can point your agent at a CLI that wipes production on the wrong flag. Neither of those is malware in the classic sense, and neither is something a virus scanner was built to catch.
So before installing a skill, you really want to know three things:
- What it claims to do.
- Whether the bundled code actually matches that claim.
- What the blast radius looks like if something goes wrong.
Answering those questions at the ecosystem scale is core to ClawHub’s mission. To take full advantage of OpenClaw, our users need to trust that the skills and plugins they install have been thoroughly vetted. Today we’re sharing how we do that work, what we found when we measured it, and a public dataset so the rest of the community can build on it.
The ClawScan Pipeline
Our first attempt at building trust was a Codex agent prompted to look for OWASP agentic risks. It worked, and it caught real bad actors. But it was a closed-source effort, and the agentic-risk problem is too new and too fast-moving for any single registry to defend on its own.
So we’re now collaborating with NVIDIA on its verified agent skills initiative, doing the work in the open. Every skill that flows through ClawHub passes a pre-catalog verification gate before it is ever published:
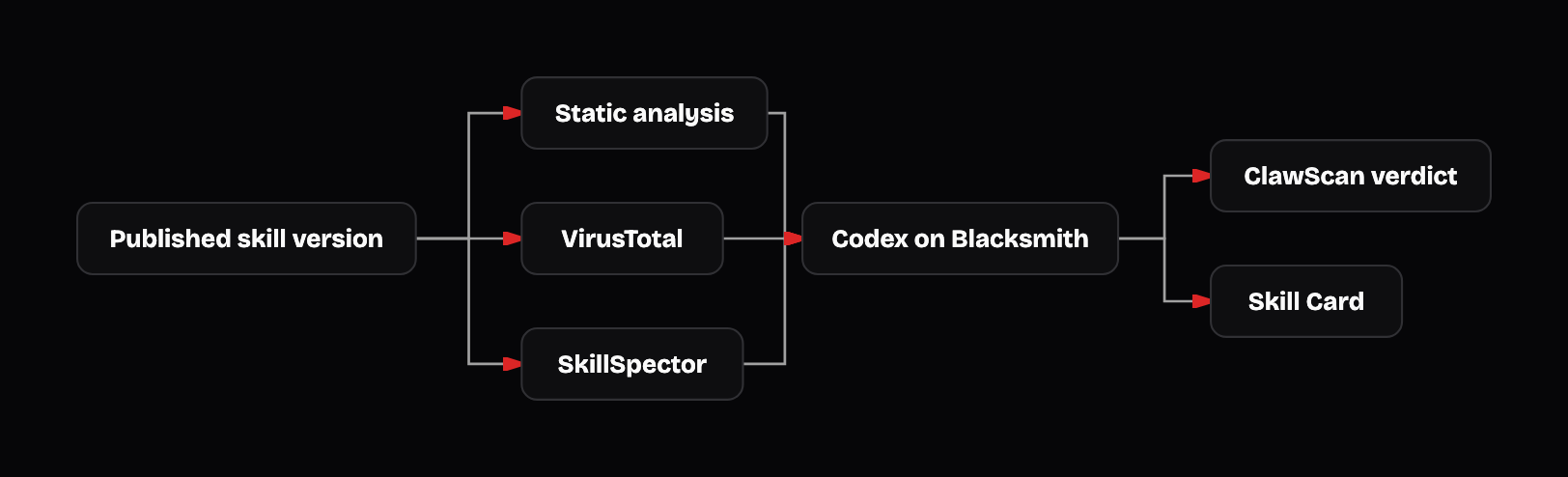
When a new skill version is published, an OpenAI Codex agent receives the output of three independent scanners as context: our static analysis, VirusTotal, and NVIDIA SkillSpector. The Evaluate step, ClawScan, weighs all three alongside provenance, metadata, and moderation history, then produces a Skill Card along with a final verdict: Clean, Suspicious, or Malicious.
NVIDIA Skill Cards and SkillSpector collaboration
Two pieces of that security process are new, and both come out of the NVIDIA collaboration.
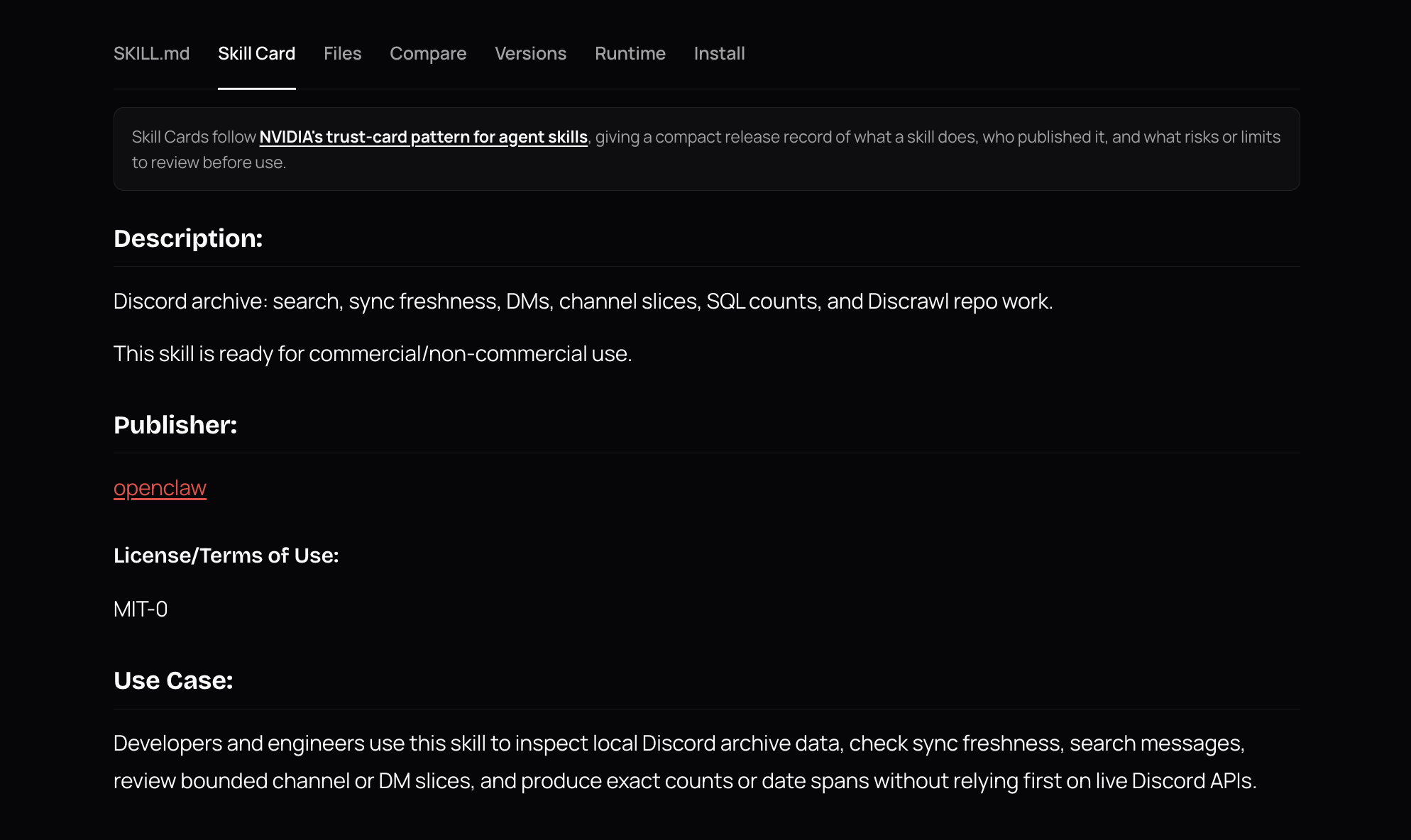
NVIDIA Skill Cards are an open trust-artifact specification, and they now ship with every published skill. Each card tells you who published it, what it can do, what ClawScan found, and exactly where it came from. These are all verified by ClawHub, not taken from the publisher’s self-description. Read it in a tab on the skill detail page, or from the terminal with openclaw skills verify <slug> --card.
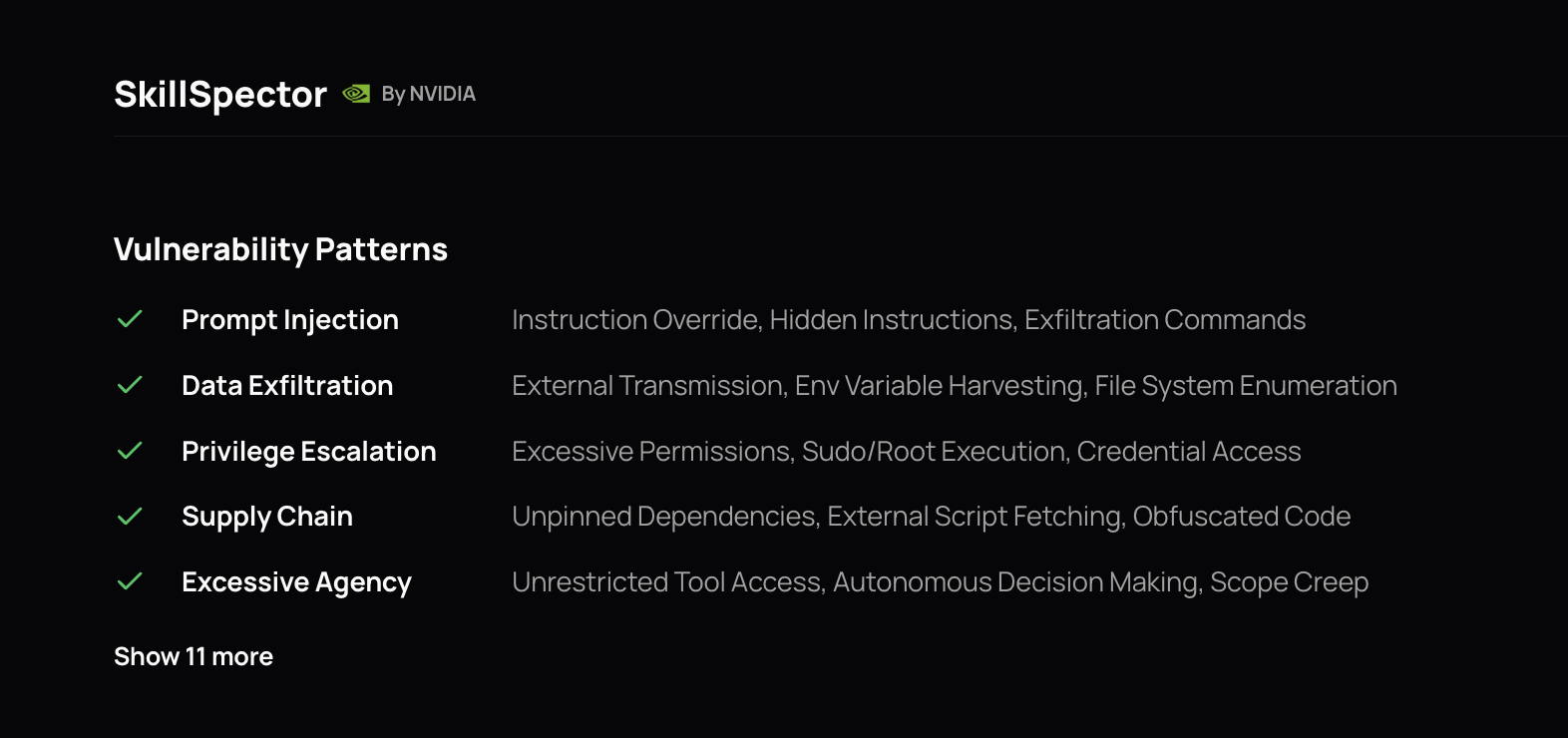
NVIDIA SkillSpector is a new agent-skill scanner. It combines static checks with AI-assisted semantic analysis to flag risks that malware scanners miss: hidden instructions, risky code paths, overbroad capabilities, dependency issues, and mismatches between a skill’s declared purpose and its actual behavior. In ClawHub, SkillSpector findings are shown as advisories; they do not automatically block a skill. ClawScan weighs them alongside everything else before reaching a verdict.
Initial findings
Our assumption was that the results from these three scanners would mostly overlap. Instead, they barely overlap at all.
| Scanner pair | Both positive | Jaccard agreement |
|---|---|---|
| VirusTotal and SkillSpector | 3,286 | 0.094 |
| Static analysis and SkillSpector | 3,511 | 0.104 |
| Static analysis and VirusTotal | 586 | 0.065 |
No pair agrees on more than 10.4% of its combined positives. Only 468 skills, or 0.69%, are flagged by all three scanners at once. 81.9% of positive findings come from a single scanner alone.
We do not believe these findings point toward an issue with any of the individual scanners. Rather, each scanner has a different risk surface. VirusTotal sees malware reputation, static analysis sees dangerous code patterns, and SkillSpector sees agentic risk. Across all 67,453 rows, SkillSpector is positive on 32,856 rows, or 48.71%, versus 5,225 rows, or 7.75%, for VirusTotal and 4,434 rows, or 6.57%, for static analysis. Within the 25,504 rows with a suspicious ClawScan verdict, SkillSpector is positive on 19,209 rows, or 75.3%. Among the 206 malicious rows, the pattern flips: VirusTotal is positive on 150 rows, or 72.8%, while SkillSpector is positive on 14 rows, or 6.8%.
These discrepancies highlight the need for an LLM-as-judge like ClawScan. Distinguishing between skills with a broad risk surface and those that are truly malicious is a novel challenge.
As one example, a skill we identified had 173 findings from SkillSpector, yet ClawScan still labeled it suspicious rather than malicious.
Rather than keep this corpus of scan outcomes to ourselves, we’re excited to open-source it for the broader security community to help us improve.
Open-sourcing our security scan signals dataset
ClawHub’s commitment to skill security does not end at our own registry. The whole community gets safer when we share what we know.
As one of the most popular skill registries, we are now running the full ClawScan suite on thousands of published events every single day, and in the process burning millions of LLM tokens with OpenAI GPT-5.5 to do so. The v1 dataset covers 67,453 latest public skill versions. This in itself is generating a huge amount of signals that would be invaluable to the security research community, but until now has been locked away inside ClawHub.
Today, we’re releasing a public dataset of all ClawHub security scan outcomes on Hugging Face: OpenClaw/clawhub-security-signals. Special thanks to Jacob Tomlinson, Agustin Rivera, and Michael Appel from NVIDIA for their contributions to this project.
Our hope is that this empowers the broader research community to join us in improving the state of the art in skill security tooling. This work is core to our mission of securing the entire agent skill ecosystem, and supporting the wider AI ecosystem.
A rising tide lifts all claws. 🦞